Ref.: Generalization
Generalization這部分在說要怎麼讓model也能適應沒新的、看過的data,只要新的data跟訓練model的data有一致的distribution,餵進model的預測應該也差不多。
我直接省略第一張圖,直接把train後的圖show出來,並讓大家看看生病的樹是橘色的點、健康的樹是藍色的點,橘色區域是很漂亮的model,讓loss超級少,每個點預測後所在的區域也非常正確。
下一張圖餵進一些黑色外框的點,看看為什麼這個model不好: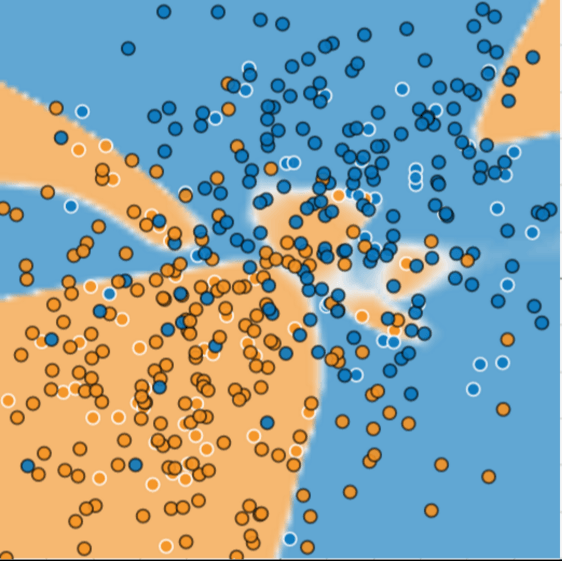
很多點落在不一樣的顏色裡,代表預測很不準,這就是overfit。
Overfit: An overfit model gets a low loss during training but does a poor job predicting new data. Overfitting is caused by making a model more complex than necessary.
但我們不能保證不會看到沒見過的data,不能保證新的data一定之前看過。Machine learning 或 AI 的最大用途就是希望能跟人一樣有學習的能力,沒看過的資料也能準確的預測。文中提到一個人**William of Ockham**,他講的名言wiki這樣翻 切勿浪費較多東西去做用較少的東西同樣可以做好的事情。
用在machine learning裡: The less complex an ML model, the more likely that a good empirical result is not just due to the peculiarities of the sample.
而文中Generalization bounds主要是看這兩個:模型的複雜度 vs. training data的效率。用它們來描述model generalize新資料的能力。但這實務上很難達成,Google這系列的課程則是以實驗後的評估為主。
也因此,即便資料已經固定數量,我們還是可以把資料分成兩個集合:
好的test set就好像是沒看過的新資料,但也要假設test set夠大,而且不會一直一直一直使用同一個test set,以免被自己騙。
好的generalization應該符合下面三個假設:
但有時候Generalize new data的時候又有可能會違反其中幾項,像是show 廣告的學習,新的廣告可能會跟看過的廣告(舊的資料)有關。因此在評估的時候也要把違反的因子考慮進去,否則如果假設已經不公正,很難說服人家你的model很準。

